Reproducable Data Science
I recently gave a talk entitled “Data Pipelines A La Mode”, with the following premise.
We can use techniques from functional programming and distributed build systems in our (big) data (science) pipelines to allow us to know what code was used for each step, not lose any previous results as we improve our algorithms and avoid repeating work that has been done already
What are data pipelines?
I will take a pretty broad definition: A set of tasks that have dependencies between them (ie one must occur after the other)
We can represent a pipeline as a Directed Acyclic Graph (DAG). It is common to just refer to a pipeline as a dag, ill do so in other bits of this article
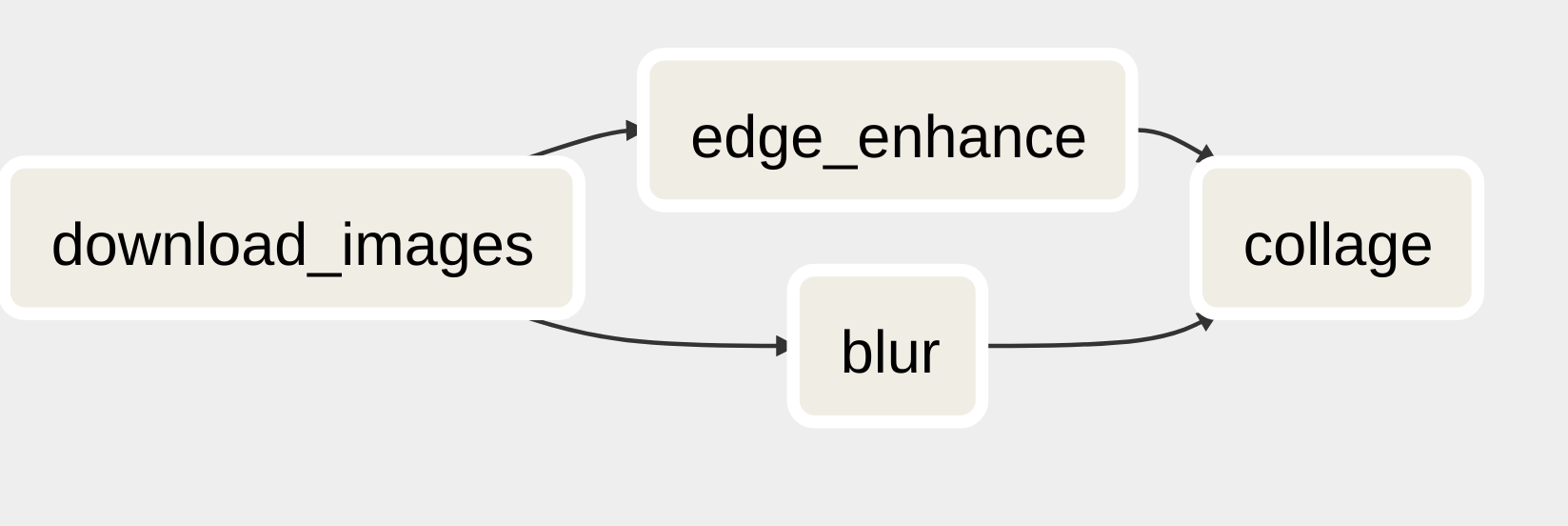
The simple pipeline we will be looking at in this article has four steps and the
following DAG. Once download_images has completed, both edge_enhance and
blur can run, then we make a collage of the results.
We can see the dag as an opportunity for parallelism
Three Things We Care About
Provenance: Do we know what data was used in a particular analysis?
Reproducibility: Can we run the analysis again?
Incrementality: If we change the dag or the tasks, can we avoid re-running things we already did?
How does being “pure” help us?
We are using the word pure in the same sense functional programming does:
A pure function is a function where the return value is only determined by its input values.
In functional programming, this means that a given invocation of a function can be replaced by it’s result, this permits memoization.
In general a task might take any actions: call external APIs, fetch data from somewhere, do something at random etc. This makes it harder to reproduce the analysis later if we need.
We will constrain our tasks so they all write their output to a single location
If a task depends on previous tasks, it should be pure in the sense it only depends on the data output by its dependencies. It should be deterministic too, for we are going to say that we get incrementality by not re-running the same task on the same data.
It can’t all be pure
Sometimes our initial inputs will be some files we already have, and we can just point at them. If not then we can have non-pure tasks at the edge “snapshotting” the world and saving it for us. We can then re-run any downstream analysis on the saved data.
Examples might be syncing from another S3 bucket (unless you have good reason to think it will remain accessible), hitting some external APIs or querying a database.
For help in understanding how to make each step pure, you should check out this blog on Functional Data Engineering or a talk by the author.
How can we represent tasks?
To keep as generic as possible, we just use an associative datastructure as in most programming languages (ie a hash/dictionary/object).
For our example dag above, assume we have a project called collage with a few
Python scripts in and we build a docker image for it. The download_images task might look like this
{
'image': 'collage',
'sha': '1qe34',
'command': "python dl_images.py"
}